FirestoreとElasticSearchを組み合わせて 検索に強いFirebaseアプリを作る
NipoPlusのバックエンドはFirebaseを使用しています。アカウント管理やストレージ、Cloud Function、データベースなどアプリ開発に必要な機能の多くが予め用意されており、Firebaseだけである程度のサービスを割と簡単に作成できます。 データの多くはFirebaseの1サービスである「FireStore」に保管することになります。FireStoreはリアルタイム同期やセキュリティルールなど、特徴のあるデータベースで、慣れてくるととても使いやすいデータベースですが、困ったことが1つあります。それが、「検索の貧弱さ」です。
FireStoreのクエリは貧弱である
Section titled “FireStoreのクエリは貧弱である”リレーショナルデータベースなどに比べるとどうしてもクエリの制限が気になります。2つ以上のキーで絞り込みをする場合はインデックスの作成が必要になってきますし、全文検索などもサポートされていません。 弱点を補って余る程の魅力があるFireStoreですが、実際にアプリを作ると様々な検索が必要になってきますのでFireStore単体だとどうしても行き詰まってしまうことでしょう。 例えば次の画面はNipoPlusでレポートを検索する画面です。
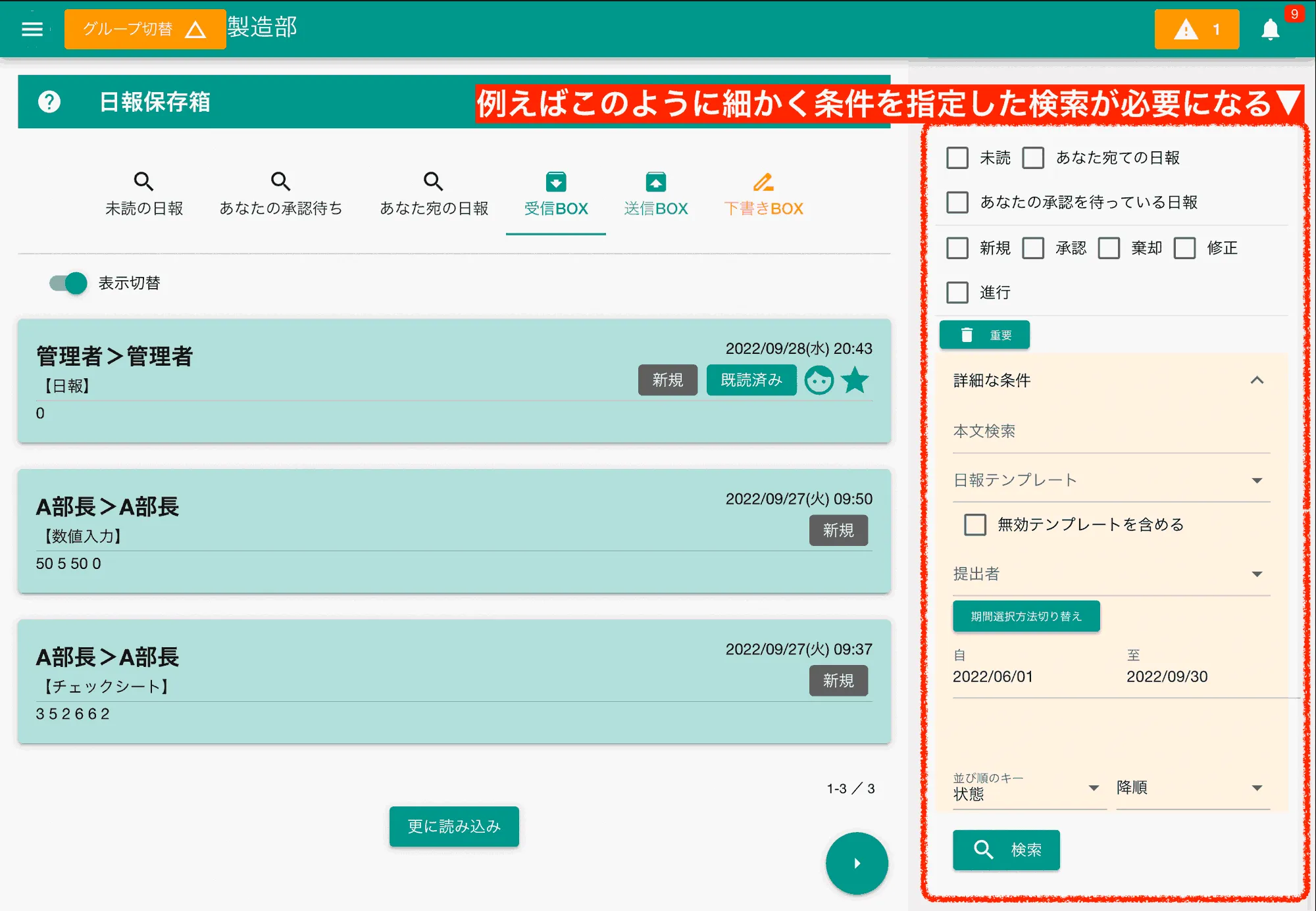
状態や期間、単語を使った検索をFireStore単体で実装しようとすると茨の道となります。フロントにデータを大量にロードしてJavascript側でフィルターを掛ける手もありますが、無駄な通信も多く処理負担も大きくなるため、あまり現実的な回避策とは言えません。 NipoPlusではこの問題に対して、FireStoreの他にElasitc Searchという全文検索対応のデータベースを併用することでこのような機能を実現しています。
Elastic Searchとは?
Section titled “Elastic Searchとは?”ElasticSearchは全文検索に対応したデータベースです。FireStoreではできない全文検索や高度なクエリを行うことができます。オープンソースで開発されており、自前でサーバを用意する場合は無料で利用できます。 自前でサーバを用意できない場合はElastic Cloudというサーバを有償で利用できます。NipoPlusはElastic Cloudを使用しています。
FirestoreとElasitc Searchを組み合わせて使う
Section titled “FirestoreとElasitc Searchを組み合わせて使う”FireStoreの便利な点と、Elastic Searchの高度な検索を組み合わせることで強力なデータベースになります。 2つのデータベースを使いますがElasticSearchはあくまでも検索専用で、メインはFireStoreです。FireStoreでデータが書き込まれたら、その変化をCloudFunctionsでキャッチしてElasticSearchへ書き込む処理をしてあげます。
Elastic Searchの準備
Section titled “Elastic Searchの準備”ElasticSearchのデータベースを準備することからはじめます。ElasticSearchではデータを保存すると良しなに型を決めてくれますが、実際は予め型(スキーマ)を決めておいたほうが良いです。 スキーマの作成は記述量が多くなるのでtsファイルなどに書き、いつでも作成出来るようにしておくとデータベースの復旧などでも使い回せるのでオススメです。 例えばNipoPlusのレポートに関するスキーマは次のように作成しています(一部紹介)
import { IndicesCreateRequest, MappingTextProperty } from "@elastic/elasticsearch/lib/api/types";
export const reportIndexName = 'インデックスの名前';const textParam:MappingTextProperty = { type: 'text', search_analyzer: 'ja_kuromoji_search_analyzer', analyzer: 'ja_kuromoji_index_analyzer', fields: { ngram: { type: 'text', search_analyzer: 'ja_ngram_search_analyzer', analyzer: 'ja_ngram_index_analyzer' }, keyword: { type: 'keyword' } }}export const reportBody:IndicesCreateRequest = { index: reportIndexName, settings: { // 日本語の全文検索設定などを記述しますが長いのでここでは省略します // 詳しくはElasticSearchの全文検索ガイドを参照してください // https://www.elastic.co/jp/blog/how-to-implement-japanese-full-text-search-in-elasticsearch }, mappings: { properties: { // ここからデータのスキーマ設定 id: { type: 'keyword' }, groupId: { type: 'keyword' }, createTs: { type: 'unsigned_long' }, owner: { type: 'keyword' }, state: { type: 'keyword' }, body: textParam, // 全文検索対応させる content: { type: 'keyword', index: false, doc_values: false } // firestoreのデータ丸コピ用。検索には使わないのでindex: falseを指定 } }}スキーマができたらこれをElasticSearchに送ってインデックスを作成します。nodejsを使って書き込む例
async function makeElastic() { const esClient = new Client({ cloud: { id: 'Elastic CloudだとCloudIDが割り当てられます。管理画面からクラウドIDを控えてここに書きます', }, auth: { username: 'username。Elastic Cloudから確認できます', password: '同上', }, })
try { await esClient.indices.create(先ほど作ったスキーマJSON) console.info('○○○○ 成功 ○○○○') } catch (e) { console.error('XXXXXX 失敗 XXXXXX') }}これでElasticSearch側の準備が完了です。 なお私はこのあたりの処理をCUIでいつでも作成・破壊が出来るようにしておきました。何かとテストで作成破壊を繰り返すことになるので、面倒臭がらず先に作っておくと開発がスムーズになります。
Cloud FunctionsでFirestoreのデータをElastic Searchへプッシュする
Section titled “Cloud FunctionsでFirestoreのデータをElastic Searchへプッシュする”Cloud FunctionsでFireStoreの変化を検出し、ElasticSearchへデータを書き込むような処理を書きます。 この例ではonWriteを使っており、書き込み、更新、削除の3つを1つのCloud Funstionsで処理しています。 なお更新はIDを指定して書き込みすれば上書きしてくれるのであまり深く考える必要はありません。mySQLで言うところのupsertみたいな感覚で使えます。
import * as functions from 'firebase-functions';import { ELASTIC_CLOUD_ID, ELASTIC_PW, ELASTIC_USER_NAME } from 'どこか遠いところからとってきて';import { Client } from '@elastic/elasticsearch';import { MYREPORT } from 'これは型定義ファイル(Nipoオリジナル)';const client = new Client({ cloud: { id: ELASTIC_CLOUD_ID }, auth: { username: ELASTIC_USER_NAME, password: ELASTIC_PW }})
/** * 例えば group/xxxxx/document/xxxxxのデータが変わったときに発火する */export const esPushReport = functions.firestore.document('group/{groupId}/document/{documentId}').onWrite(async (change, context) => { const groupId = <string>context.params.groupId; const documentId = <string>context.params.documentId;
const index = '先ほど作ったElasticのインデックス名'; if (!change.after.exists) { // Firestoreからデータが削除された場合は、ElasticSearchからも削除しないといけません。 await client.delete({ index: index, id: documentId }); return; }
const FSReport = <MYREPORT>change.after.data();
const v = { index: index, id: documentId, document: { // ここでElasticSearchのスキーマに合うような形に変形させておきます。 // FirestoreとElasticSearchは互換性がありそうで微妙に形が変わるのでそこだけ注意 body: FSReport.body, content: JSON.stringify(FSReport) } } try { // Elasitic Searchへ書き込み処理 await client.index(v); } catch (e) { functions.logger.error(e); }})これでFireStoreのデータとElasticSearchのデータをほぼ同じ状態に保つことができます。 処理の流れは絶対に Firestore => Elastic Searchの一方通行になるように意識しています。相互通信してしまうとわけがわからない事になりかねないため、この流れは絶対遵守します。
データの検索はCloud Functionsを経由して行う
Section titled “データの検索はCloud Functionsを経由して行う”ElasticSearchのデータは大切なデータなのでセキュリティ上、安全に守られながら運用しなければなりません。FireStoreであればセキュリティルールを使うことでデータを安全に保護できますが、ElasticSearchにはセキュリティルールがありません。 ElasticSearchには独自のアクセス権限などが設定できますが、あくまでもFireStoreの補助として使う場合、ElasticSearchのアクセス権限を設定してしまうと話がこじれてしまいます。 そのため、NipoPlusでは、ElasticSearchにアクセスできるのはCloud Functionsからのみとし、Cloud Functionsで全ての権限チェックを行っています。 FirebaseのユーザIDを保証できるhttpOnCallを使うと、アクセスユーザの素性がわかるので便利です。
以下はサンプルです。
import * as functions from 'firebase-functions';import { DocumentReference, getFirestore } from 'firebase-admin/firestore';import { Client } from '@elastic/elasticsearch';import { authError, ELASTIC_CLOUD_ID, ELASTIC_PW, ELASTIC_USER_NAME } from '../_components/const';import checkUserHogehoge from './check';import { QueryDslQueryContainer, SearchRequest } from '@elastic/elasticsearch/lib/api/types';import { CFQueryParam } from '../if';import { FSGroup } from '@FRONT/if';
/** * クエリ実行の例。フロントからのリクエストで発動する。contextの中にはアクセス者のFirebaseIDなどが格納されているため、これらの情報を使い適切な権限を確認します */export default functions.https.onCall(async(data, context) => { try { // 詳細は明かせませんが、起動直後に権限のチェックをしっかり行い、権限不足は速攻弾くような仕組みを作っておくと良いです。 // Cloud Functionsはセキュリティルールを貫通してアクセスできるので特に念入りにチェックします await checkUserHogehoge({ context: context }); if (result.result === false) { return result; } } catch (e) { return { error: true, message: 'あなたはふさわしくないわ' }; } // 第一関門のセキュリティチェックを抜けたらElasticSearchに問い合わせする準備が始まります。 const client = new Client({ cloud: { id: ELASTIC_CLOUD_ID }, auth: { username: ELASTIC_USER_NAME, password: ELASTIC_PW } }) const elasticFilter:QueryDslQueryContainer[] = [] // Elastic のクエリでFilterをセットします。例えばアクセス可能なユーザで絞り込むなど。 // context.auth.uidは正しいIDであることが保証されるためFilterに使うことで安全性が高まります。 // セキュリティルールが使えないので特に念入りに! elasticFilter.push({ term: { owner: context.auth?.uid } }); // mustやshouldなど様々なクエリが使えます。今回は簡略のため空欄のままです。 const must:QueryDslQueryContainer[] = []; const should:QueryDslQueryContainer[] = []; // 最終的にクエリの形になるように組み立てます。 const query:SearchRequest = { // ここではdataのチェックを省いていますが、dataはフロントからのパラメータのため本当はちゃんと正しい値かチェックしたほうがよいです index: data.index, from: data.from, size: data.size, sort: data.sort, query: { bool: { filter: elasticFilter, must: must, should: should, must_not: data.mustNot } } } // Elasitic Searchへ問い合わせをします const esRes = await client.search(query); const returnVal = { total: esRes.hits.total, hits: esRes.hits.hits } // ElasticSearchの結果をフロントに返却します return returnVal;})結果をフロントに返却し、フロントはフロントで受け取ったデータを良しなに表示します。
他の全文検索データベースとの比較
Section titled “他の全文検索データベースとの比較”Firebaseの公式サイトでも全文検索を行うには外部DBを使う方法を紹介しています。 紹介されているデータベースは以下の3種類です。
- Elastic Search
- Algolia
- Typesense
全てのデータベースを使ってみましたが、ElasticSearchは導入までの手間が最もかかる面倒くさいデータベースです。 AlgoliaやTypesenseではアクセス制限をもったAPIキーを生成出来るので、権限を適切にセットしたAPIキーをフロントに渡せばフロントから直接AlgoliaやTypesenseにアクセスできるため、 開発自体が非常に簡単に進められます。 箱から出してすぐ使えるというメリットはありますが、Algoliaはコストが高すぎる。Typesenseは検索精度が低すぎるというデメリットがあります。 単語をスペースで区切らないCJK(日本語・中国語・韓国語をまとめてCJKといいます)を母国語とする場合、検索精度を上げるために色々苦労することになります。
ElasticSearchはこの点、kuromojiやngramといった検索精度を高める仕組みをスキーマ定義の際に設定できるため比較的高い検索精度を保つことができます。 また、AlgoliaやTypesenseに比べてかなり複雑なクエリを書くことも出来るため、長い目で見るとElasticSearchを導入するのがベストな選択だと思いました。 例えばTypesenseは文字によるソートがそもそもできない。Algoliaはソートのキーを1種類しか指定できないなどの弱点がありますが、ElasticSearchはガンガン使えます。