Firestoreのポイントインタイムリカバリでバックアップ。実際に一部の復元もやってみた
ポイントインタイム リカバリによりFirebaseのデータをバックアップできるようになります
Section titled “ポイントインタイム リカバリによりFirebaseのデータをバックアップできるようになります”いやぁ、ついに来ましたね。2023年夏、Firestoreはこれまでまともなバックアップ機能が有りませんでしたが、ついに公式からバックアップ機能が実装されました。 本記事執筆時点でこの機能はまだ「プレビュー版」ですが、非常に期待しています。
詳しくは本家記事を御覧ください。
簡単にまとめると
- 最大7日間のバックアップ
- バックアップ期間の時点にいつでも戻れる
- 無料枠での利用はできないのでGOLDPLAN必須
- まだプレビュー版
というところでしょうか。 Firebaseを使い始めて5年ほどが経過します。これまでの間に、多くの便利な機能がどんどん実装されてきました。 インクリメントの実装や配列内の検索機能、Collection Groupなんかも以前は有りませんでした。 そして今回ついにバックアップの実装。いやはや、Firebaseはどんどん便利になっていきますね。
ポイントインタイムリカバリを使って実際にデータを一部のみ復元してみた
Section titled “ポイントインタイムリカバリを使って実際にデータを一部のみ復元してみた”さて、実際にポイントインタイムリカバリ機能を使う機会があったので、備忘録も兼ねて記事にしたいと思います。 完全に復元する場合は簡単ですが、今回はとあるドキュメントとその配下のサブコレクションすべてを復元する必要がありました。そのため、少し回りくどい手順を踏む必要があります。 大まかな流れを説明すると次のような手順になります。
- バックアップのバケットを作る(一時保管用)
- 復元用のFirestoreを作る
- 復元用のFirestoreにデータを流し込む
- 復元用のFirestoreから本稼働のFiresoreに復元したいドキュメントのデータを流し込む
こんな感じでやります。 作業時にはいくつか控える項目があるので先にリストアップしておきましょう。
- バケット名
- ファイル名
- データベース名
この3つが登場します。混同しないようにしっかり分けてコピペしてください。
一時保管用バケットを作る
Section titled “一時保管用バケットを作る”復元したい時点のFirestoreスナップショットをBucketにコピーします。 GCPにログインし、適当なBucketを作っておきましょう。
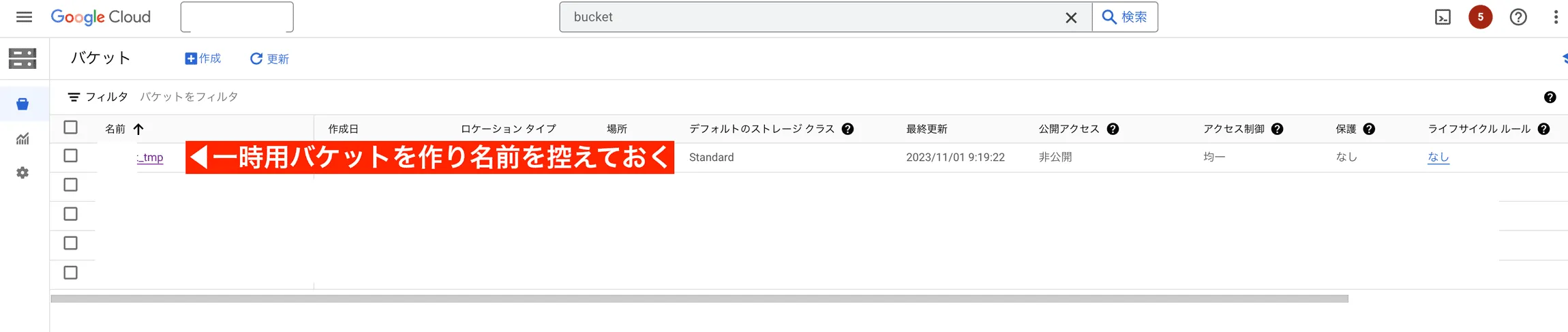
ここではバケット名を nipoplus_tmp とします。バケット名はあとから使うので忘れずにメモして下さい。
バケット名: nipoplus_tmp
復元したい時点でのスナップショットを先程作ったバケットに保存します
Section titled “復元したい時点でのスナップショットを先程作ったバケットに保存します”直近1週間以内の任意の時点でバックアップを取得できます。バックアップを取得し、先ほど作ったバケットにバックアップを保存します バックアップの取得はGCPのターミナルから行います
gcloud alpha firestore export gs://[バケット名] --snapshot-time=[復元したい時刻][]の中身は適時書き換えてください。例えば以下のように書きます▼
gcloud alpha firestore export gs://nipoplus_tmp --snapshot-time=2023-10-31T10:20:00.00Z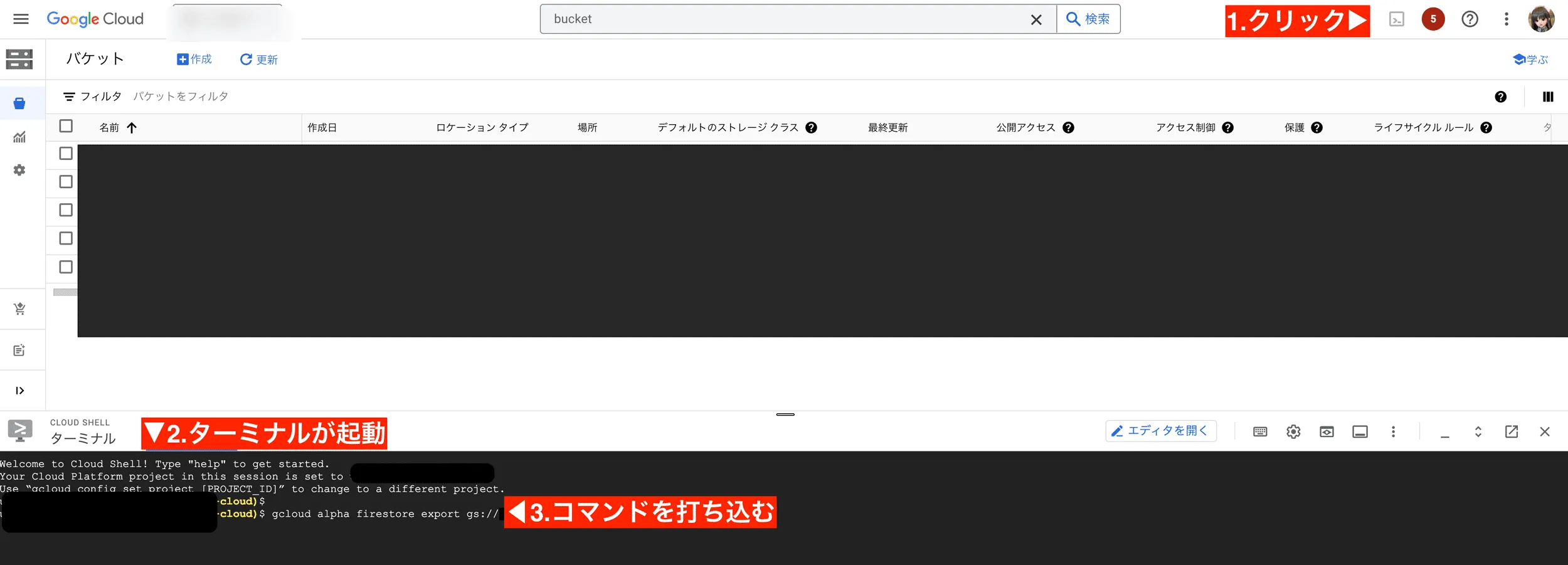
バックアップが作成されるとバケット上に追加されます。確認しておきましょう。
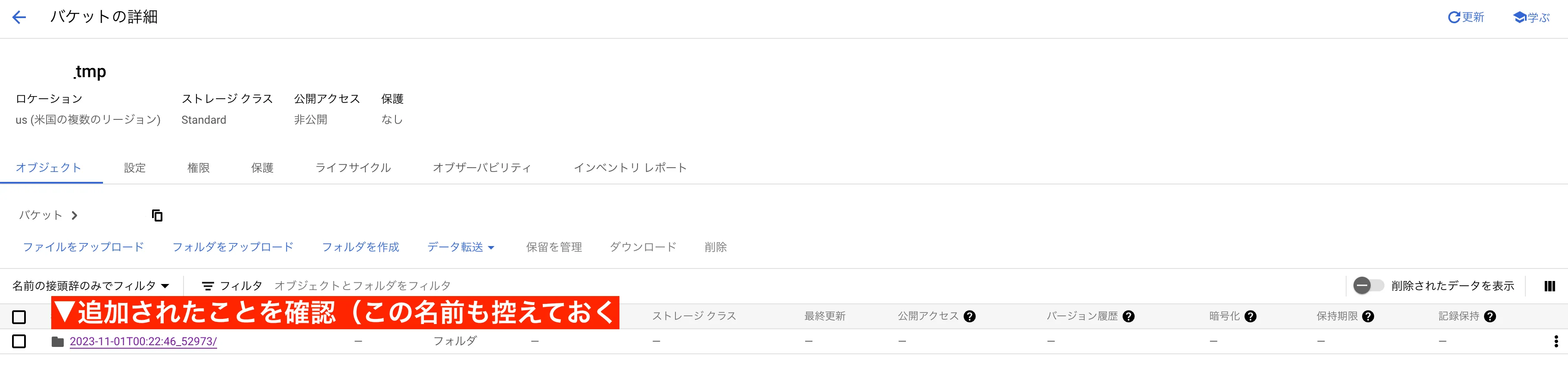
バケット内に作成されたファイル名は後に使用するので、パスを含めてファイル名を控えておきます。
ファイル名: nipoplus_tmp/2023011-01T〜 のような形式
復元用のFirestoreを作り、スナップショットのデータを復元用Firestoreにインポートする
Section titled “復元用のFirestoreを作り、スナップショットのデータを復元用Firestoreにインポートする”さてバックアップデータを開いてみてもよくわからない連続した数字ファイルの集まりであり、そのままでは使用できません。 せめてJSON形式だったら・・・と思いますが残念ながらバイナリファイルのため何もできません。 このバックアップファイルをFirestoreに取り込めば復元は完了しますが、今回は「特定のドキュメントとその配下の全サブコレクション」を復元したいので、少し回りくどいですが復旧用にもう1つのFirestoreを作りそこに復元します。 Firestoreは本記事執筆時点ではコマンドから作る必要があります。 以下のコマンドでFirestoreを作れます。
gcloud alpha firestore databases create --database=[作成する DB 名] --location=us-west1 --type=firestore-native作成するDB名は今後の工程で使うので控えておきます。 データベース名: nipoplus_recover
作成してから画面をリロードし、Firestoreをひらくと追加したDBがリストに増えていることが確認できます。
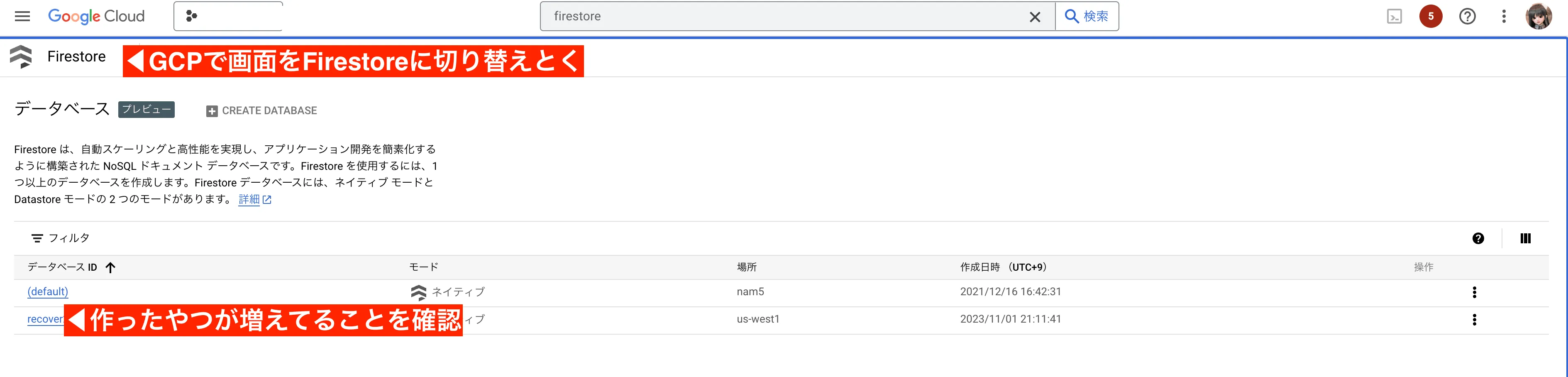
これまで控えてきた名前を使います。今一度確認してみましょう。
- ファイル名: nipoplus_tmp/2023011-01T〜 のような形式
- データベース名: nipoplus_recover
この情報をターミナルに入力します
gcloud firestore import gs://[ファイル名] --database=[データベース名]これで復元用のFirestoreにデータが書き込まれます。この時点でまだ本番には一切手を触れていません。
復元DBから本番DBへ一部のデータを移動する
Section titled “復元DBから本番DBへ一部のデータを移動する”ここからはかなり慎重に作業する必要があります。本番のデータベースにデータを書き込むので、ミスしたら大問題です。 念のためバックアップを撮っておくのも良いでしょう。
さて、FireStore全体の復元、または特定のコレクションの復元はGCP上からできます。 しかし特定のドキュメント以下を復元する機能は用意されていないため、自前で実装する必要があります。
例えば /user/{userId}/配下のデータだけ復元したいってケースは結構あると思うんですけどね。残念ながら機能としては用意されていないので自前で実装します。
私はNodejsで実装しました。拙いコードですが共有しておきます。
import { initializeApp, cert, getApps, getApp } from 'firebase-admin/app'import { FIREBASE_CERT } from './const'import { getFirestore } from 'firebase-admin/firestore'
const BATCH_LIMIT = 500const app = getApps().length === 0 ? initializeApp({ credential: cert(FIREBASE_CERT) }) : getApp()
// 本番で稼働しているFireStoreconst defaultDb = getFirestore(app)// 復旧用のFirestore。第二引数にデータベース名を指定しますconst recoverDb = getFirestore(app, 'nipoPlus_recover')let batch = defaultDb.batch()let opsCount = 0
/** * @param src Firebaseの復元したいドキュメントパス。例: /company/4DeCz6E5MxzlczFeAgfv/customer/4akxxQ6chqzu1jqJdHBx * @param dist 書き込み先のパス。srcと同じパスを指定すれば、復旧用DBー>本番用DBへ同じパス上に書き込みされます。異なるパスを指定することもできます */export async function recovery(src: string, dist: string) { /** 復元用DBのパス */ const sourceDocRef = recoverDb.doc(src) /** 本番用DBのパス */ const targetDocRef = defaultDb.doc(dist) console.time('recoverFn timer') try { await fetchRecursive(sourceDocRef, targetDocRef) if (opsCount > 0) { batch.commit() // 残りのバッチをコミット } } catch (error) { console.error('エラーが発生', error) } console.timeEnd('recoverFn timer')}
/** * 1ドキュメント単位で再起させる */async function fetchRecursive(sourceDocRef: FirebaseFirestore.DocumentReference, targetDocRef: FirebaseFirestore.DocumentReference) { const doc = await sourceDocRef.get() if (!doc.exists) return
const data = doc.data() batch.set(targetDocRef, data) opsCount++
// バッチの制限を超えた場合、バッチをコミットして新しいバッチを開始 if (opsCount >= BATCH_LIMIT) { console.log('バッチ書き込みを実行します...') await batch.commit() batch = defaultDb.batch() opsCount = 0 }
const collections = await sourceDocRef.listCollections() for (const collection of collections) { const docs = await collection.listDocuments() for (const doc of docs) { console.log('再帰: NextPath->', collection.id, doc.path, opsCount) await fetchRecursive(doc, targetDocRef.collection(collection.id).doc(doc.id)) } }}こんな感じのコードを書いて、あとは実行します。 緊張の一瞬ですね。こういう本番のデータベースをいじるのは心臓に悪いのでできればやりたく有りません。 上記コードをお試しいただく場合は、入念に確認のうえ行ってください。
このプログラムは特定のドキュメントパスを受け取る(src)と、復元用データベースのドキュメントを取得し、それを本番用データベースのパス(dist)上に書き込みます。 サブコレクションがあれば再帰的に調査して読み取り、書き込みをバッチで行います。
簡単に言えば指定したドキュメントパスをルートとし、その中の全てのサブコレクション、サブドキュメントを復元します。 復元処理には多少時間が掛かります。(1000ドキュメントでおよそ2分ほど掛かります。)
必要に迫られて実際に復元したときの流れを記述してみましたがいかがでしたか? 実はテスト環境ですが顧客データを間違えて消してしまい、急遽復元が必要になったのです。 全体を復元させてしまうと、正常な他の顧客のデータが「巻き戻る」事になってしまうため、全体の復元を使うわけには行きませんでした。 そのため、今回のような回りくどい手法で復旧させました。
いやしかし、全体を復元させるってのは楽でしょうが、あれはほんとうの意味での最終手段ですね。 影響範囲が大きすぎるので、そう手軽には使えないなぁと改めて実感しました。
Firestoreは非常に優れた製品ですが、バックアップと復元はまだちょっと不便なところが多くあるなと感じた騒動でした。